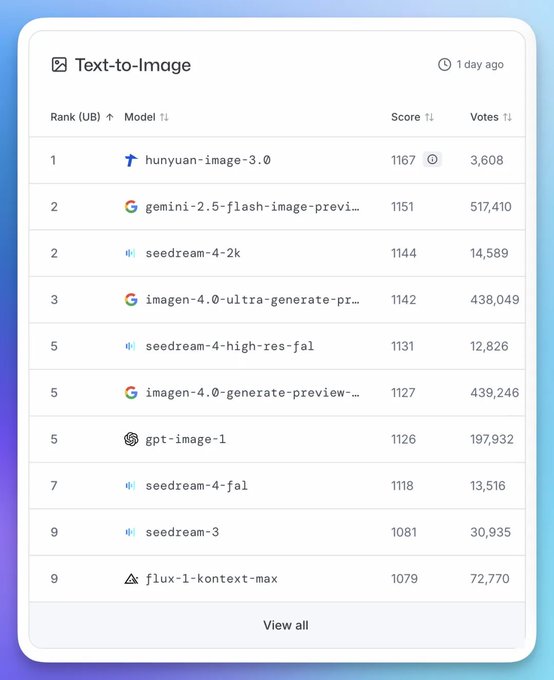
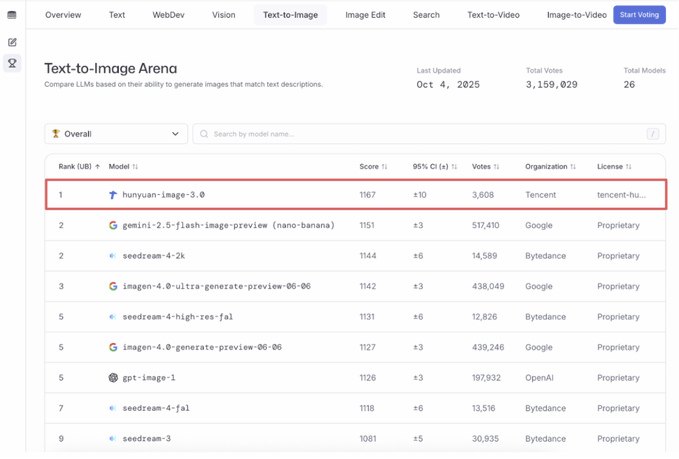
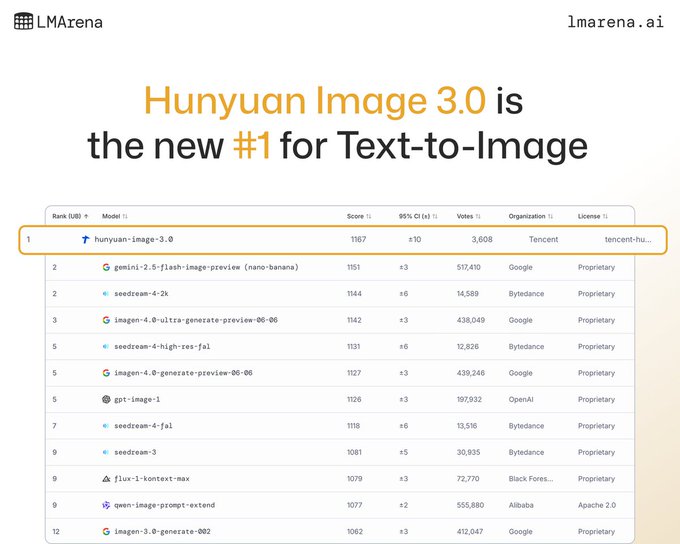
Tencent's Hunyuan Image 3.0 is insane. It's currently the top overall and top open-source Text-to-Image model in the Arena beating Nano Banana and Seedream.




觀看展示騰訊混元影像 3.0 強大 AI 影像生成能力的演示和教學
觀看展示騰訊混元影像 3.0 強大 AI 影像生成能力的演示和教學
看看大家在 X (Twitter) 上對混元影像 3.0 的評價
Tencent's Hunyuan Image 3.0 is insane. It's currently the top overall and top open-source Text-to-Image model in the Arena beating Nano Banana and Seedream.
Hunyuan Image 3.0 Prompt { "Objective": "Create a fashion magazine cover image featuring a man and woman in a cinematic, artistic setting.", "Scene_Details": { "Main_Subjects": { "Gender": ["Male", "Female"], "Pose": "Standing still, looking directly at the Show more


今天早晨起来,看到混元图像3.0竟然登顶 LMArena 文生图模型榜单第一名,成了世界第一的文生图模型。 LMArena是目前国际上最权威的AI模型竞技场榜单,采用完全匿名的盲测机制。 就是在这个榜单上,混元图像3.0击败了 Google 的 Nano Banana、OpenAI 的 GPT 4o Show more
I’m going to Mars. At least according to the AI-generated ticket I just printed. Fully readable, poster-worthy, and 100% created with an open-source model. Here’s 10 crazy things Hunyuan Image 3.0 can do:

Hunyuan Image 3.0, de Tencent, se ha asegurado el primer puesto mundial en la última evaluación de texto a imagen de LMArena. El 28 de septiembre, Tencent lanzó una bomba: HunyuanImage 3.0. Un modelo multimodal nativo, de código abierto y con parámetros de 80B. ¿Traducción? Show more

O melhor modelo para geração de imagem a partir de texto é de código aberto! O modelo chinês Hunyuan Image 3.0 superou o Gemini 2.5 Flash Image Preview, também conhecido como nano Banana 🍌.
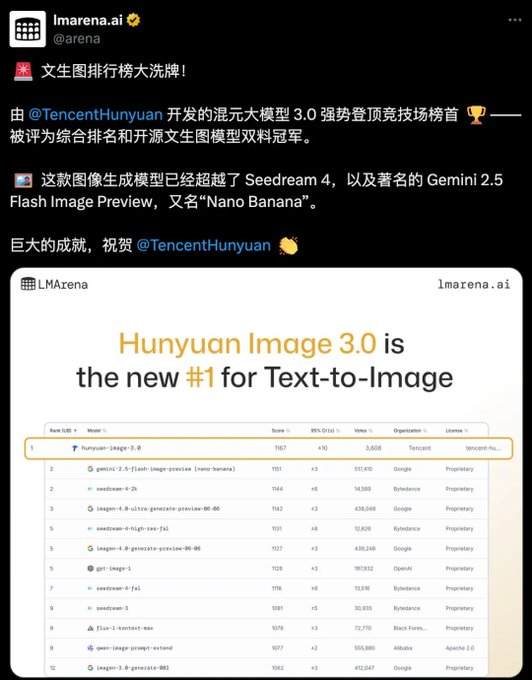
腾讯混元图像3.0,在LMArena平台的全球26个顶级AI模型盲测中,以用户真实投票获得文生图领域第一 超越Google、OpenAI等国际巨头,包括此前热门的nano-banana模型 发布仅一周即登顶Hugging Face热榜,展现了快速的市场认可度
We now have the most comprehensive lineup of generative 3D models on @Scenario_gg, from Hunyuan 3.0 to Hithem3D, Rodin, Meshy, Tripo, Trellis, and more! All in one place, plus image & video generation. Check it out: app.scenario.com/3D/
There’s no other platform with as many generative 3D models as Scenario. app.scenario.com
騰訊突破性的AI影像生成模型,具有卓越的中英文文本能力
混元影像3.0基於800億參數的MoE架構,具有130億活躍參數,是首個實現原生中英文文本渲染卓越性能的開源模型。
探索令混元影像3.0成為中英文文生圖AI生成理想選擇的先進功能
在中英文兩種語言中具有卓越的文本生成能力,完美渲染複雜字元同排版。
採用800億參數的專家混合架構,透過專家路由提供卓越性能同計算效率。
利用廣泛的世界知識進行高級推理,生成上下文準確且語義豐富的影像。
以出色的準確性處理超長文本提示詞,在擴展描述中保持上下文。
在Apache-2.0開源許可下可用於商業用途,可自由集成無許可限制。
生成高達2048×2048像素的影像,支援多種寬高比,適合專業應用。
集成視覺-語言理解與高級多模態處理,生成具有精確語義對齊的影像。
對影像構圖具有卓越的控制能力,智慧佈局理解準確放置元素。
掌握混元影像3.0的文生圖功能
用中文或英文創建包含主題、風格、構圖和文本內容具體細節的綜合提示詞,以實現準確渲染。